数据湖分析与U-SQL在UCloud中立云计算服务中的实践与价值
在当今大数据时代,企业面临着海量、多样、快速变化的数据处理挑战。数据湖作为一种集中式存储库,能够以原始格式存储海量结构化、半结构化和非结构化数据,为数据分析与挖掘提供了广阔的舞台。而U-SQL作为一种专为大数据处理设计的查询语言,结合UCloud中立云计算服务商的强大数据处理服务,为企业构建高效、灵活的数据湖分析体系提供了理想的解决方案。
一、数据湖分析的核心价值与挑战
数据湖的核心优势在于其“先存储,后处理”的模式。企业无需在数据摄入前预先定义严格的模式,可以保存原始数据,后续根据需求灵活提取、转换和分析。这大大增强了数据的可访问性和处理灵活性,支持从批处理到实时分析、从机器学习到可视化报表的多样化应用场景。
数据湖的构建与管理也面临诸多挑战:如何高效处理PB级甚至EB级数据?如何确保数据处理过程的性能与成本效益?如何在不同计算框架(如Spark、Hive)间无缝切换?这正是U-SQL与专业云计算服务商发挥作用的领域。
二、U-SQL:统一大数据处理的强大工具
U-SQL(Unified SQL)是微软开发的一种混合查询语言,结合了SQL的声明式简洁性与C#的强大扩展能力。它专为大规模数据处理设计,原生支持Azure Data Lake Analytics等平台,其核心特点包括:
- 统一处理能力:U-SQL支持对结构化、半结构化(如JSON、XML)和非结构化数据的统一查询,用户无需为不同数据源切换工具。
- 可扩展性:通过内嵌C#代码,用户可以自定义提取器(Extractor)、处理器(Processor)和输出器(Outputter),满足复杂的数据清洗、转换需求。
- 高性能执行:U-SQL作业在分布式环境中自动并行化执行,能够高效处理超大规模数据集。
- 成本优化:按处理数据量计费,用户无需预置昂贵硬件,特别适合波动性数据处理任务。
三、UCloud中立云计算服务商:安全、可靠的云底座
UCloud作为国内领先的中立云计算服务商,坚持“不与用户竞争”的中立原则,专注于提供稳定、安全、高效的云计算基础设施。在数据处理服务领域,UCloud提供了一系列与数据湖分析高度契合的产品:
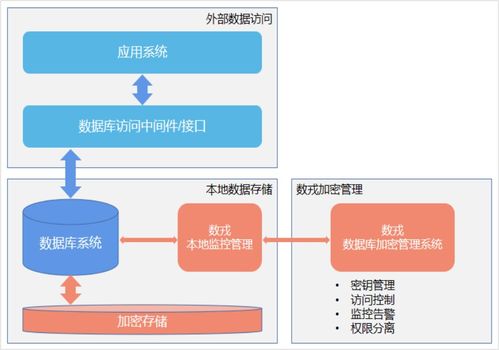
- UCloud数据湖存储(UFile/UFS):提供高可靠、低成本的对象存储与文件存储服务,适合作为数据湖的底层存储层,支持海量数据持久化。
- UKafka与UDTS:提供实时数据接入与传输服务,确保数据从源头顺畅流入数据湖。
- 弹性计算与容器服务:提供UHost(云主机)、UK8S(Kubernetes服务)等,为运行U-SQL作业或其他计算框架(如Spark on K8s)提供弹性资源。
- 安全与合规保障:通过等保三级、ISO27001等认证,满足金融、政务等行业对数据安全与合规的严格要求。
四、U-SQL在UCloud环境中的数据处理实践
结合U-SQL与UCloud服务,企业可以构建端到端的数据湖分析流水线:
场景示例:电商用户行为分析
1. 数据摄入:用户点击流日志(JSON格式)通过UKafka实时写入UFile对象存储。
2. 数据清洗与转换:通过U-SQL作业(调度执行)读取原始日志,利用C#自定义逻辑清洗无效记录、解析复杂嵌套字段,并转换为Parquet列式存储格式,提升查询性能。
3. 数据分析:使用U-SQL进行多维度聚合分析(如用户会话统计、热门商品排行),结果写入UCloud关系型数据库(UDDB)或分析型数据库(ClickHouse on UCloud)供报表使用。
4. 机器学习集成:将处理后的特征数据输出至UCloud GPU云主机,用于训练推荐模型。
优势体现:
- 成本可控:UCloud按需计费模式与U-SQL按处理量计费结合,避免资源闲置。
- 灵活扩展:UCloud弹性资源池可随时应对数据峰值,U-SQL作业自动分布式并行。
- 生态开放:UCloud支持混合云与多云部署,U-SQL可与其他开源框架(如Spark)协同,避免厂商锁定。
五、未来展望
随着数据湖架构的演进,Lakehouse等新范式正逐渐兴起,强调数据湖的可靠性、性能与事务支持。UCloud作为中立云服务商,持续迭代其数据产品线(如推出托管Spark服务、增强对象存储智能分层能力),与U-SQL这类高级查询语言相结合,将帮助企业在保持架构开放性的获得接近数据仓库的管理体验。
###
数据湖分析并非单一技术之战,而是存储、计算、安全、成本多方平衡的艺术。U-SQL以其强大的统一处理能力,与UCloud中立、安全、弹性的云计算服务相结合,为企业提供了一条高效、经济且自主可控的数据价值挖掘路径。在数字化转型的浪潮中,选择合适的技术栈与云服务伙伴,将是企业构建数据驱动竞争力的关键一步。
如若转载,请注明出处:http://www.jxfreespace.com/product/22.html
更新时间:2026-06-18 08:17:22